In den letzten 2 Beiträge haben wir angeschaut, wie man eine AnnotationListe schreibt und sie mit einem Canvas eines Manifests verbindet. Demnach habe ich jetzt beispielsweise ein Manifest und eine Annotationslist gemacht. Dabei habe ich das Beispiel-Manifest in dem früheren Beitrag genommen. Und dies zuerst Omeka classic aufgenommen und dort die Annotationen hinzugefügt. Von Omeka classic her habe ich wiederum die AnnotationsListe geholt und sie umgeschrieben. (Dieser Schritt ist normalerweise nicht nötig. Wir machen dies nur, um die Verbindung zwischen der Annotationliste und dem Canvas zu lernen)…
Dies ist die URL zur Annotationslist… Relativ simple… Und weil wir die Annotation gucken wollen, sollen wir die URL des Manifest in einem IIIF-Viewer öffenen, mit dem man Annotation ansehen kann… Z.B. Mirador
Wenn man auf Home-Seite von Mirador geht, klickt man «Try a live demo». Dann öffnet der Viewer. Jetzt die zwei Bilder/Item schliessen, indem man das Kreuz-Symbol von Links oben anklickt.
Dann «Start here» klicken.
Weiter «Add resource» klicken.
Da kann man die URL des Manifests eingeben und öffnen. Dann sollte man das Item im Mirador viewer ansehen. In diesem Zustand «Toggle bar» einblenden, indem man das 3-Balken-Symbol klickt.
Dann sieht man einen orangenen Punkt zum Sprechblasen-Symbol.
Dann tauchen 4 Annotationen schon… Wenn man hier das Augen-Symbol klickt, werden die markierten Bereiche sichtbar, für die die Annotationen geschrieben sind. Also es hat geklappt!
Wir können eigentlich jetzt problemlos IIIF-Manifest erstellen, zumal man dafür z.B. Omeka classic verwendet. Wenn man sich für weitere technische Sachen nicht interessiert, kann man ein geeignetes System wie Omeka S, Omeka classic, oder Kitodo, installieren. Oder es gibt anscheinend einen Alma-Cantaloupe-Image-Server in Github, mit dem man vielleicht die digitalen Bilder durch Cantaloupe und Alma (Bibliotheksverwaltungssystem vom Exlibris) nach IIIF-Standard publizieren kann (allerdings weiss ich zu wenig dafür)…
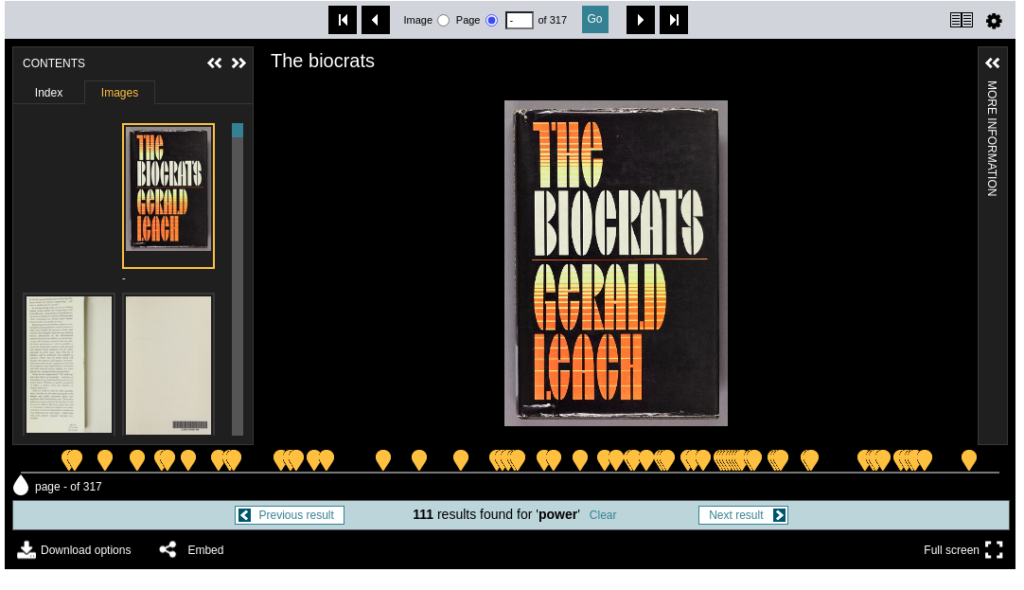
Aber hier würde ich ansehen, wie man eine Annotation nach IIIF-Standard zu einem Bild anbringen kann. Als Beispiel nehmen wir mal das digitalisierte Buch von the Wellcome Library:
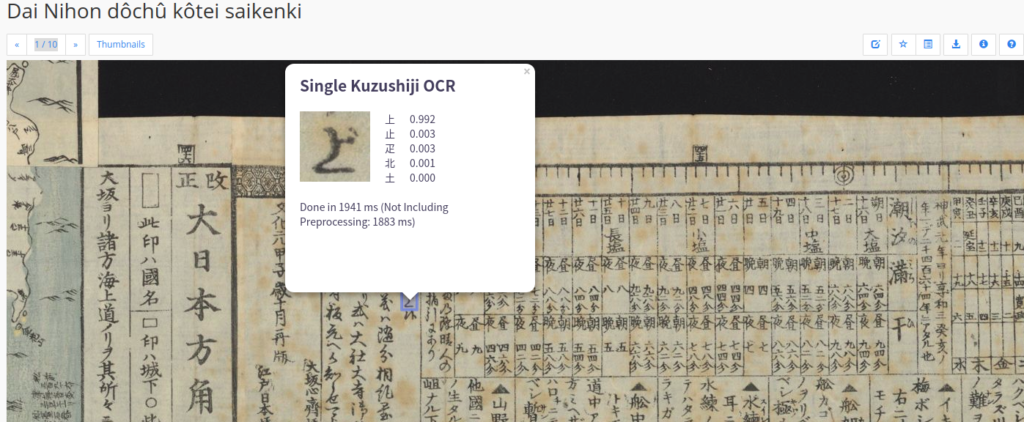
Wenn man dort das digitale Buch ansieht, sieht man unten am Bildrand ein Suchfenster mit «Search within this item». Dort kann man ein Suchwort eingeben. Dann tauchen die Textstellen, wo das Suchwort enthalten ist. Also ich schreib› mal z.B. ein Wort wie «power» dort. Dann kommen Ergebnisse:
Die entsprechenden Seiten sind mit den orangenen Marker unten markiert. Das bedeutet, dass das Buch nicht als Bild sondern als Text erschlossen ist… Wie geht das? Annotation!
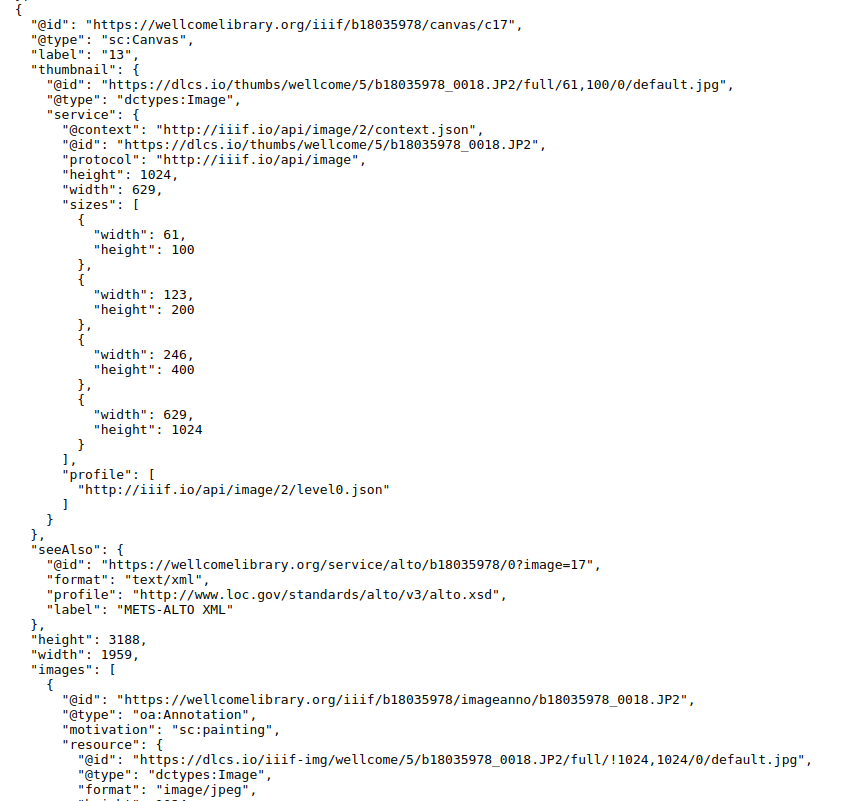
Dort betrachten wir beispielsweise das 17. Canvas. Das beginnt so:
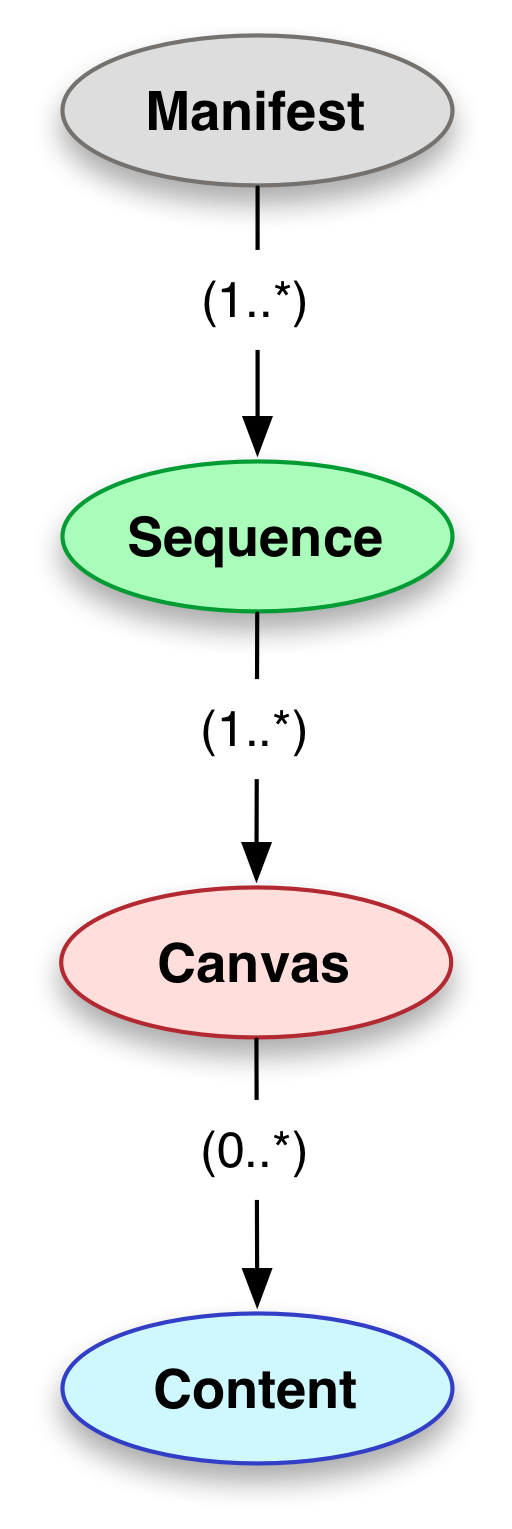
Die Struktur ist uns schon bekannt. Zuerst wird das Canvas in einer Sequenz definiert. Danach wird das Image auf dem Canvas hinzugefügt.
Welches Image auf dem Canvas kommt, wird durch «@id» unter «resource» bestimmt. Auf demselben Canvas kann man jedoch Annotation auch noch hinzufügen.
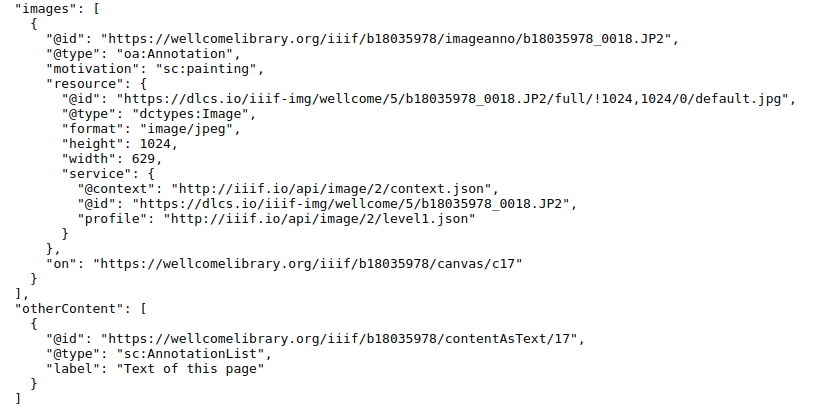
Unter «images»-Property kommt hier ein weiteres Property «otherContent» hinzugefügt. Dort unter «@type»-key steht AnnotationsList. Dies ist also die Annotationslist, die mit dem 17. Canvas verbunden ist. Die AnnotationsList ist so mit dem Canvas verbunden. Wie sieht dann die Annotationsliste aus?
Zum Beginn der Liste wird durch 3 Properties das Dokument definiert. Die ID einer Annotationsliste ist nach Presentation API von IIIF so definiert [link].
Recommended URI pattern: {scheme}://{host}/{prefix}/{identifier}/list/{name} […] The annotation list must have an http(s) URI given in @id, and the JSON representation must be returned when that URI is dereferenced.
Danach sind unter «resources» einzenle Annotation als Arrey aufgelistet. So wie es aussieht, sind einzelne, zu annotierende Bereiche (wahrscheinlich Zeile) durch «#xywh=» auf dem Canvas definiert. Der Inhalt der einzelnen Annotation ist unter «resource» festgelegt. Hier handelt sich hauptsächlich um den erschlossenen Text. So werden einzelne Annotationen auf einer AnnotationsList mit dem jeweiligen Bereich auf dem Canvas verbunden.
Mit Omeka classic + Plugin «IIIF Toolkit» werden wir hier eine Annotationsliste erstellen. Zuerst in Omeka classic einloggen – und dann «IIIF Toolkit» öffenen, indem man den gleichnamigen Button in der linken Spalte klickt.
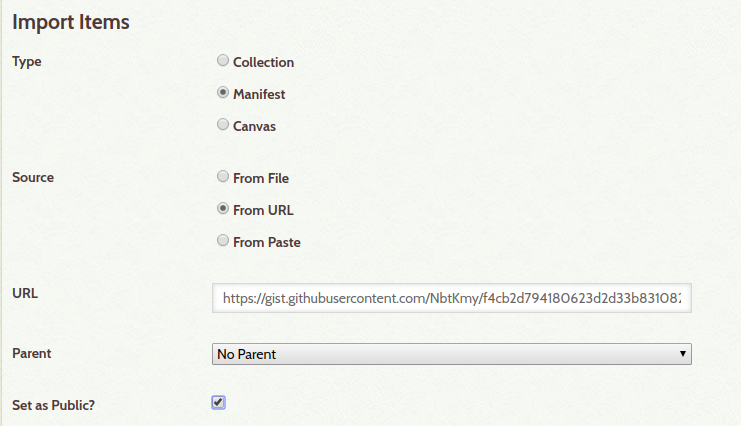
Wir wollen ja ein existierendes IIIF-Manifest in Omeka importieren. Daher geben wir die Parameters folgendermassen ein:
Type – Manifest
Source – From URL
URL – die URL zum eigenen IIIF-Manifest
Set as Public? – Anhaken
Wenn’s gut geht, wird das Item importiert. Und dies wird im Omeka als «completed» angezeigt:
Dann – «Collection» klicken
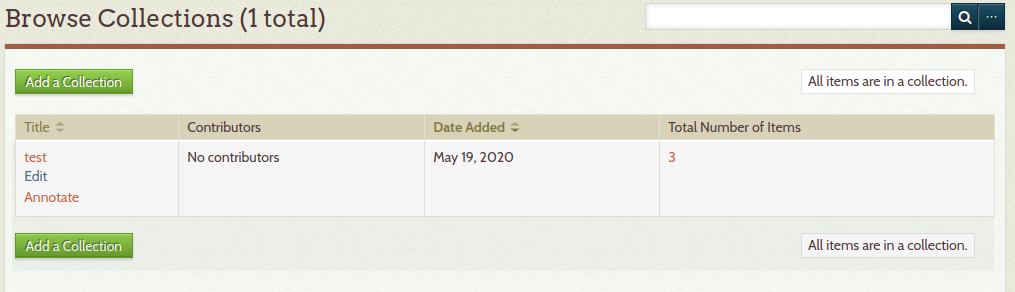
So wird unser importiertes Manifest angezeigt. Nun dort «Annotate» klicken.
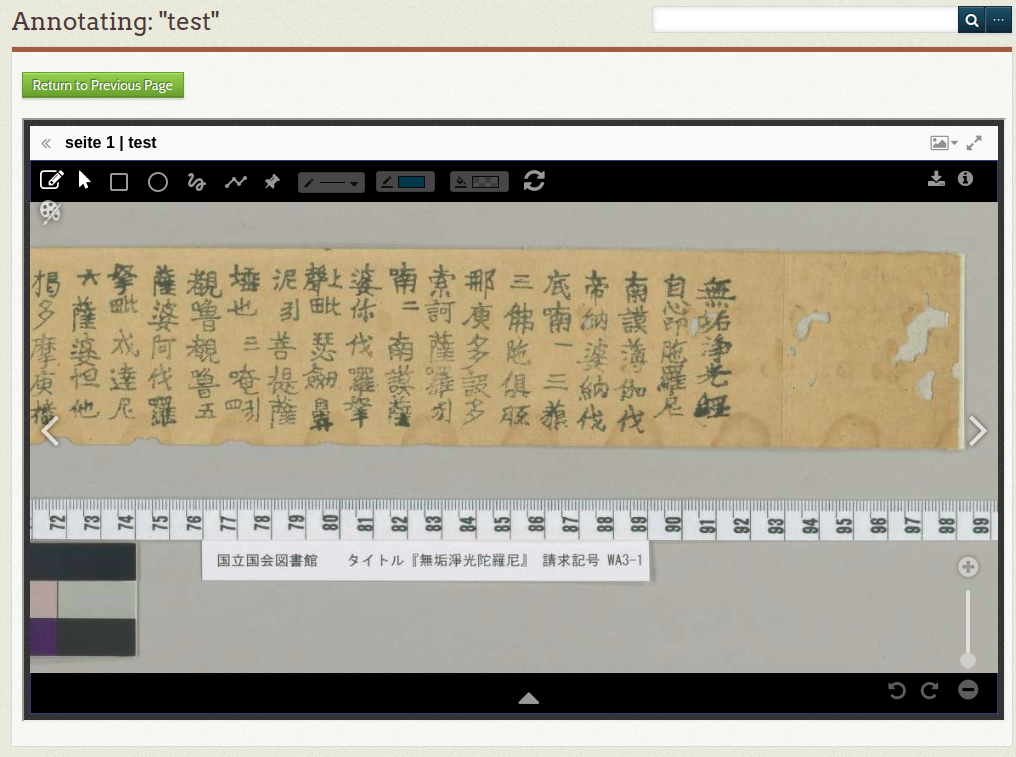
Und dann kann man hier annotieren…Das Rechteck-Symbol klickenMit dem Rechteck den Bereich markieren. Dann kommt ein Popup-Fenster vor. Da kann man die beliebigen Annotationen und Tags hinzufügen. Public? – Anhaken. Wenn alles fertig ist, «save» klicken.
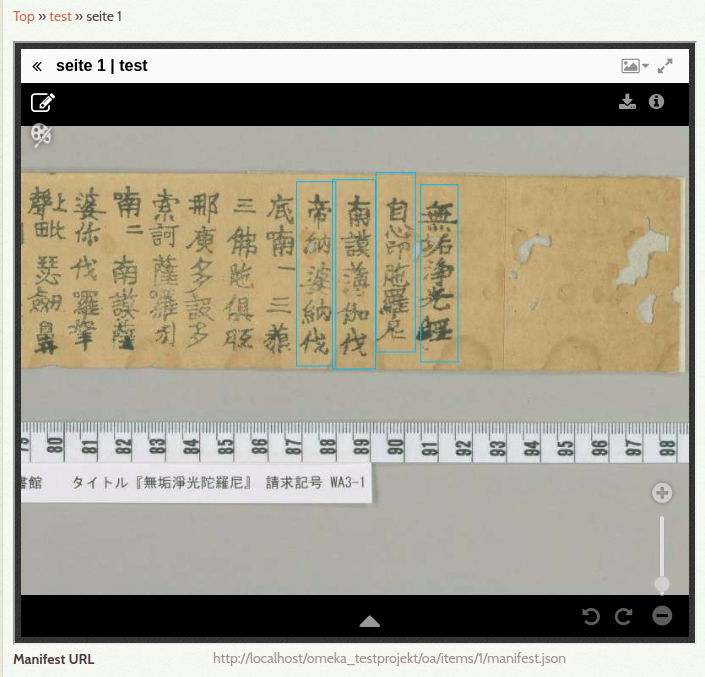
Ich habe hier 4 Zeile transkribiert und die Transkription als Annotation auf der Seite 1 hinzugefügt. Man sieht dementsprechend 4 Kästchen, wenn man auf «Items» geht und dort die Seite 1 anzeigt. Unten bei dieser Anzeige sieht man auch «Manifest URL». Wenn man die URL in einem anderen Tab des Browsers öffnet, sieht man das Manifest für diese Seite. In diesem Manifest sieht man die Zeile:
Unter der URL «http://localhost/omeka_testprojekt/oa/items/1/annolist.json» gibt es unsere begehrte Annotationsliste.
… Wenn man die Web-Publikation sowieso mit Omeka classic macht, braucht man eigentlich keine weitere Aktion mehr. Weil wir aber mit den JSON-Dateien ein wenig genauer ansehen wollen (vor allem wie die Annotationsliste und IIIF-Manifest verbunden sind), tüfteln wir die beiden JSON-Dateien, IIIF-Manifest und Annotationsliste in dem nächsten Beitrag.
Weil wir einiges über IIIF wissen, installiere ich mal ein System, durch das man praktische Tools wie IIIF toolkit usw. verwenden kann.
Das System heisst Omeka Classic. Dies ist ein CMS (Content management system), mit dem man sehr einfach unterschiedliche Objekte mit Metadaten beschreiben kann und sie ins Netz stellen kann. Omeka hat zwei Varitane – eines ist Omeka classic, und das andere Omeka S. Omeka classic ist eher für ein individuelles Projekt geeignet. Omeka S ist als ein Content management system für ein (kleinere) Institution gedacht. Dies ist die URL zur Homepage: https://omeka.org/
Ich habe in meiner lokalen Umgebung (auf eigenem PC) im Voraus die notwendigen Sachen installiert: OS: Ubuntu 16.04 LTS PHP 7.4 Apache2 (2.4.18) MySQL (5.7.30)
Nach System requirements von Omeka classic (Ver 2.7.1) habe ich darüber hinaus noch php-mysql (wegen PHP extention mysqli) installiert. exif war bereits installiert bei mir. Darüber hinaus habe ich mod_rewrite durch «$ sudo a2enmod rewrite» aktiviert. Sonst habe ich die Anleitung für Installation gelesen. Ich dachte, es wäre genug…
… Natürlich reicht das nicht… Bei Installation bekam ich aber folgende Fehlermeldungen:
mod_rewrite nicht aktiviert
Dom PHP extention
Zugriffserlaubnis für alle Ordner unter «files» wie «fullsize», «thumbnails» usw.
mod_rewrite nicht aktiviert
Dies ist bereits in Community thematisiert (s. link). Es reicht nicht mit dem Befehl «$ sudo a2enmod rewrite» (damit zeigt Apache-Server eigentlich, dass rewrite-Mode aktiviert sei). Man muss darüber hinaus die Konfiguration vom Apache-Server «/etc/apache2/sites-available/000-default.conf» umändern und eventuell auch die Konfigurationsfile «apache2.conf» unter /etc/apache2/. So wie die Community besprochen wurde, sollen die Zeile unten in die beiden Konfigurationsfile hinzugefügt werden:
In «/etc/apache2/sites-available/000-default.conf» sollen die Zeile innerhalb Virtual-host-Tag hinzugefügt werden. Wenn man die Konfiguration geändert hat, muss man den Server neu starten wie «$ sudo service apache2 restart» – So solle das Problem gelöst sein.
Dom PHP extention
Dafür habe ich lediglich noch php-xml installiert («$sudo apt install php-xml»). Und wieder der Apache-Server neu gestartet…
Zugriffserlaubnis für alle Ordner unter «files» wie «fullsize», «thumbnails» usw.
All die Ornder unter «files» müssen schreibbar sein, so wie die Instruktion steht:
Make Omeka’s storage directory and its sub-directories writable by the web server. For Omeka 1.5.3, the directory is archive. For Omeka 2.0+, the directory is archive. For Omeka 2.0+, the directory is files. You can change the permissions yourself with an FTP or other file transfer program, or with shell commands over SSH. If you’re not sure what to do, ask your host for advice, or to change the permissions for you.
Daher mit dem Befehl bsplw. «$chmod 766 [Name des Ordners]» die Permissionen ändern.
Wenn alle Fehler beseitigt sind, gelangt man auf die Installationsseite. Dann folgt man weiterhin der Anleitung von Omeka classic!
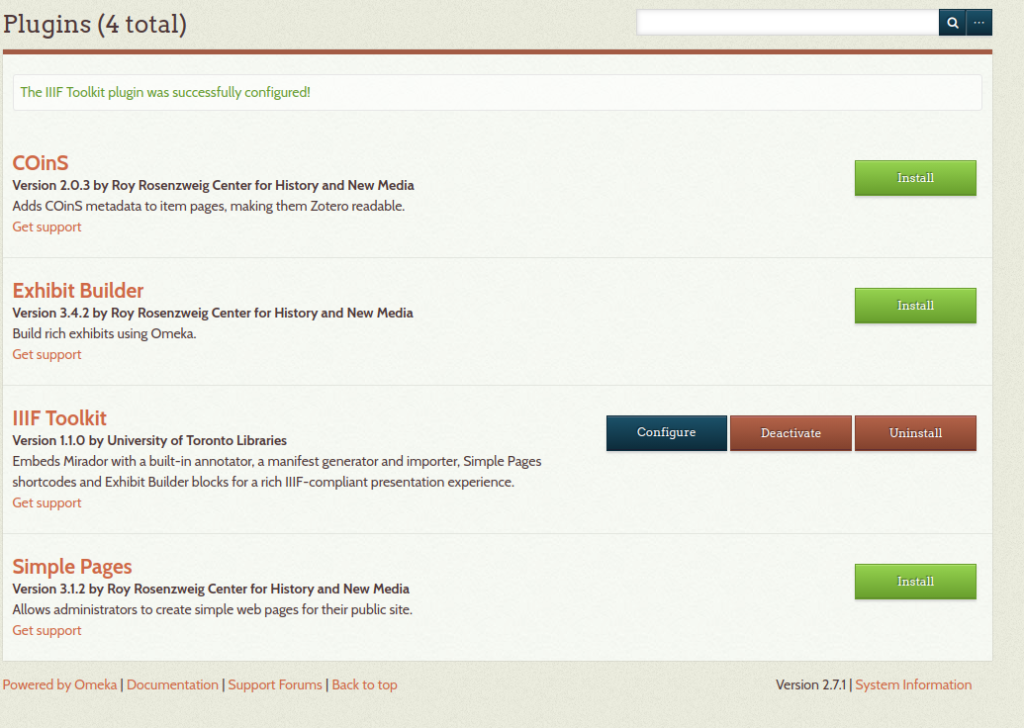
Weil man später die IIIF-Annotation mit IIIF-Toolkit ausprobieren will, wird hier gleich das Plugin «IIIF-Toolkit» in Omeka classic installiert.
Für dieses Plugin gibt es zwei Voraussetzungen für die Installation:
Omeka Classic 2.3 and up
IIIF image server pointing to the Omeka installation’s files/original directory (optional if you will only be importing content from existing manifests)
Da wir das neueste Version von Omeka (ver 2.7.1) genommen hat, ist die erste Voraussetzung bereits erfüllt. Für das zweite Voraussetzung – wir importieren hier nur IIIF-Manifest. Daher müssen wir sie nicht jetzt erfüllen – Also kein Problem.
Zuerst das Plugin herunterladen, indem man den Button «Download 1.1.0» auf der rechten Seite des Plugins klickt. Dies wird als Zip-File heruntergeladen. Entpacken diese Zip-File in den Ordner «plugins» unter Omeka classic-Ordner. Dann so wie in der Anleitung fürs Plugin steht:
Sign in as a super user.
In the top menu bar, select «Plugins».
Find IIIF Toolkit in the list of plugins and select «Install».
If you plan to serve your own images via IIIF, see «Pointing a IIIF image server» for details. [Dies ist hier nicht notwendig]
Wir haben in den letzten Beiträge ein IIIF-Manifest erstellt und ins Netz gestellt. Das Manifest ist jedoch allein die Code in JSON-Format. Es zeigt das Bild ja nicht. … Schade ist es. Daher hier die Einführung zur Anwendung des UV (Universal Viewer)
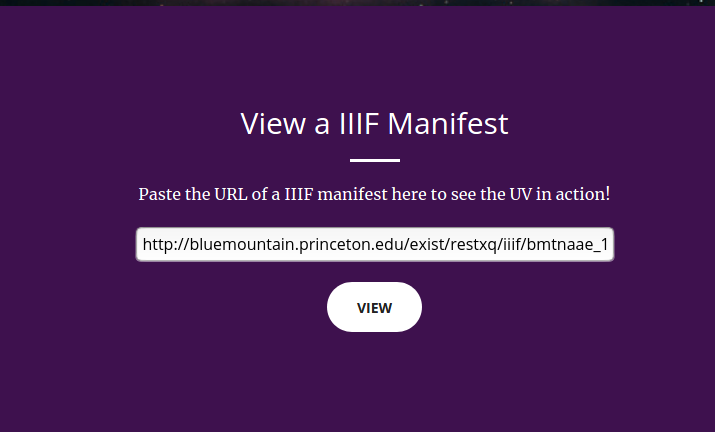
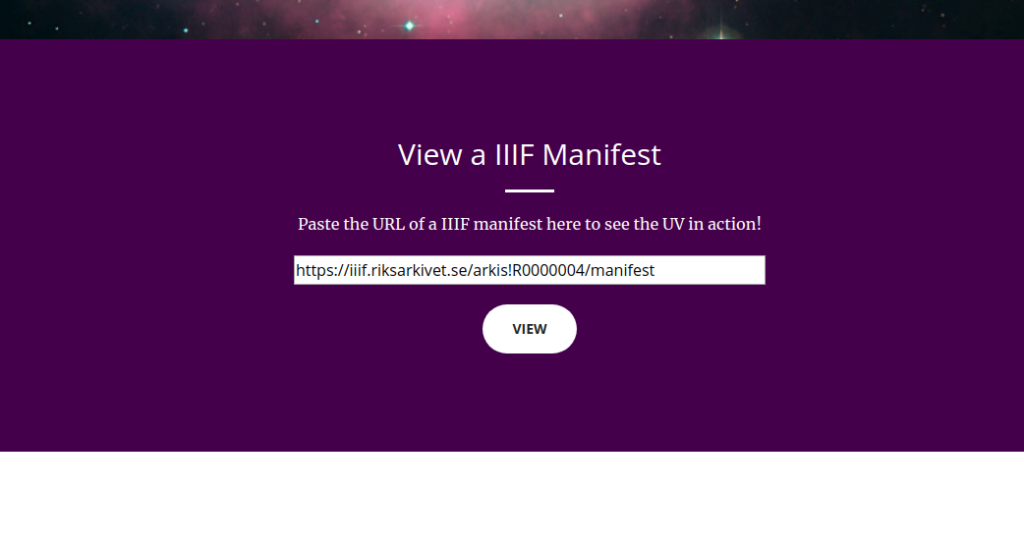
Ich gehe hier davon aus, dass man die URL zu dem eigenen IIIF-Manifest hat und dass CORS (Cross-Origin Resource Sharing) für das Manifest zugelassen ist. Diese URL bitte bereitstellen. Dann geht man auf die Home page des UV und nach unten scrollen.
Dann kommt man diese Sicht. Ihr sieht ja dort schon «Paste the URL of a IIIF manifest here […]» – Also machen wir’s. Dann sollte die Bilder, die man im IIIF Manifst zusammengestellt hat, im UV angezeigt. Irgendwie so:
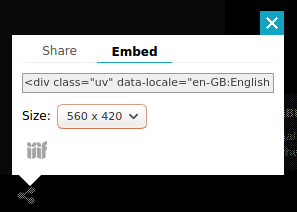
Man sieht hier links unten das Symbol zum Sharing.
Wenn man darauf klickt, springt ein Fester hervor.
Hier wähle ich «Embed» –
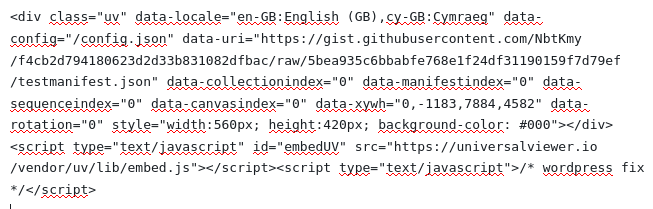
Da kann man die Grösse mit Pulldown-Menü holen. Wenn die Grösse in Ordnung ist, kopiert man die Code «<div class=»uv»[…]>» Es sieht irgendwie so aus:
Diese Code kann man z.B. in irgendeine HTML-Seite oder in einem Blog-Seite hinein kleben. Dann wird das Bild mit UV auf der HTML-Seite oder wo auch immer angezeigt.
Bei diesem Vorgang holt man jedoch den UV von dem fremden Anbieter (also UV-Domain) und nicht von sich selbst. Wenn man die URL vom Viewer betrachtet, sieht man es deutlich. «https://universalviewer.io/vendor/uv/lib/embed.js»
Wenn man doch auch den Viewer auf dem eigenen Server haben will, soll man den UV holen. UV hat Github-Seite. Dort gibt es Source-codes, die man auch selbst entwickeln könnte. Wenn man aber nur den Viewer haben will, kann man da den UV holen, der bereits ge-«build»et ist. Ich habe bei Version 3 (V3) oder aufwärts keine Code «embed.js» gefunden. (Anscheinend ist es seit Feb. 2019 so? s. issue) Demgegenüber bei UV-2.0.2 fand ich sie. Daher nehmen wir hier UV-2.0.2.
Wenn man auf die Github-Seite des UV reinkommt, sieht man zuerst «Master»-Version. Da muss man auf «v2» hingehen. Die direkte URL ist hier. Dort unten gibt es ein Zip-Datei.
Dies kann man auf den eigenen Rechner herunterladen. Wenn man die ZIP-Datei aufmacht, sind viele Codes zu finden. Unter dem Ordner «uv-2.0.2» gibt es einen Ordner «lib». Und weiter in dem Ordner gibt es «embed.js». Also der Code befindet sich im Ordner «uv-2.0.2/lib». Man kann diese Zip-Datei auf den eigenen Server hochladen. Und die Zip-Datei dort in dem Ordner aufmachen, dessen Inhalt online sichtbar sein wird. Dann hat man den UV bereits auf dem eigenen Server. Dann soll man nur noch die URL vom UV (also «https://universalviewer.io/vendor/uv/lib/embed.js») mit dem Pfad zum eigenen UV ersetzen.
Wie in dem letzten Beitrag angekündigt, schauen wir hier, wie man IIIF Manifest Editor verwenden kann.
Mit dem Editor, der von der Bodleian Library, Univ. of Oxford, entwickelt wurde, kann man sowohl ein vorhandenes Manifest weiter editieren, als auch ein neues Manifest erstellen.
Es ist jetzt relativ klar, dass wir hier «New Manifest» anklicken sollen…
Dann kommt man auf diese User Interface. Auf der rechten Seite findet ihr 3 Balken «Manifest metadata», «Sequence metadata» und «Canvas metadata». Diese Struktur haben wir in dem letzten Beitrag schon gesehen.
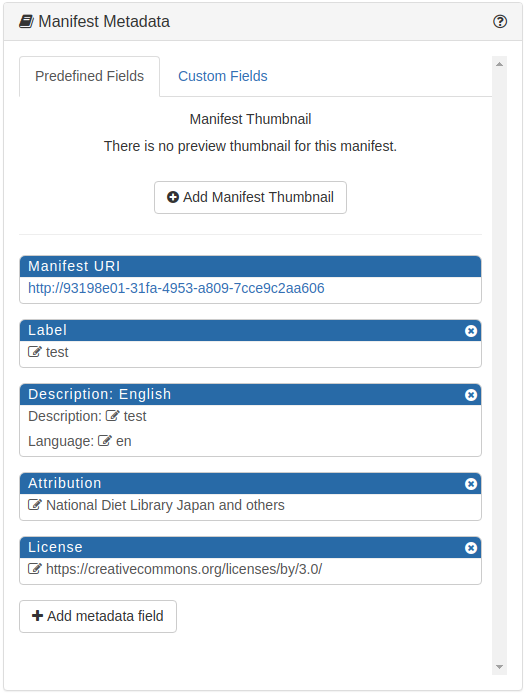
Zunächst habe ich eine einfache Metadaten für das Item geschrieben…
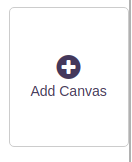
Da fehlen jedoch noch Bilder, die wir im Viewer zeigen lassen wollen. Dafür fügen wir zuerst ein Canvas pro Bild im Manifest hinzu – Also das Symbol «Add Canvas» klicken.
Dann taucht eine leere Fläche mit «Empty canvas» auf. Diese Fläche klicken und aktivieren. Danach die Balken «Canvas metadata» klicken.
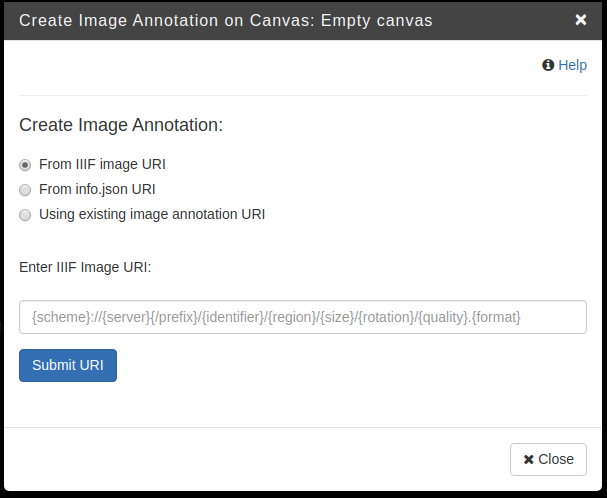
Dadurch wird das Arbeitsfläche für Canvas-Bereich geöffnet. Und da steht «Add Image to Canvas»! – Natürlich klicken!
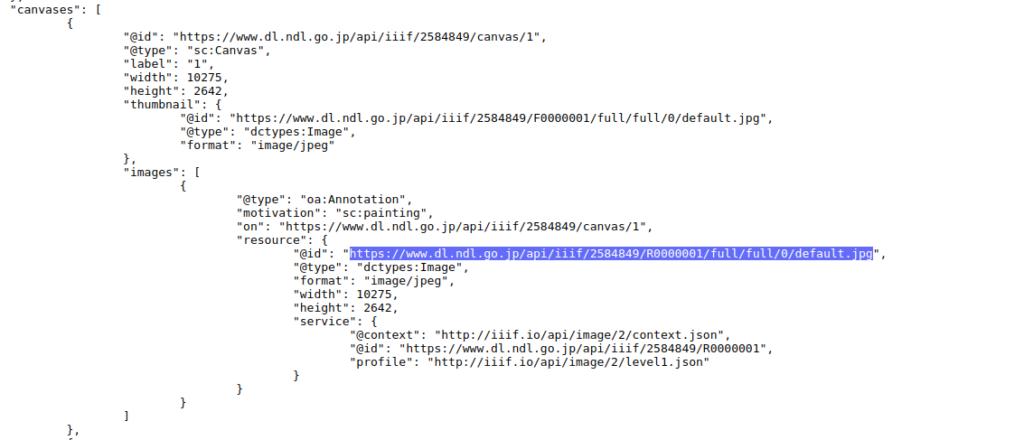
Hier können wir die URI zu IIIF-Bilder, die wir durch Cantaloupe Image Server ins Netz gestellt haben, hinzufügen. Solange IIIF Image öffentlich zur Verfügung gestellt ist, kann man auch beliebige IIIF Image hier einsetzen. Um am Beispiel des Bildes von der NDL zu bleiben, nehmen wir IIIF-Bild von dem letzten Beitrag. Im IIIF Manifest, das die NDL anbietet, steht IIIF image URI hier:
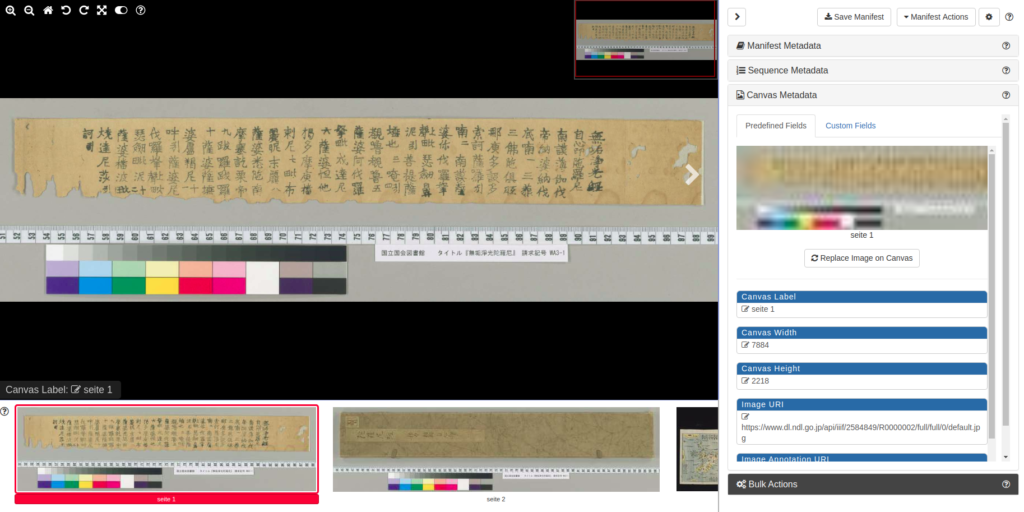
Dann wird das Bild auf dem Canvas aufgenommen. Die Grösse (Höhe x Breite) des Canvas wird nach dem Bild automatisch eingegeben. Man kann noch einzelne Canvas beschrieben, in dem man in «Canvas label» die Beschreibung hinzufügt.
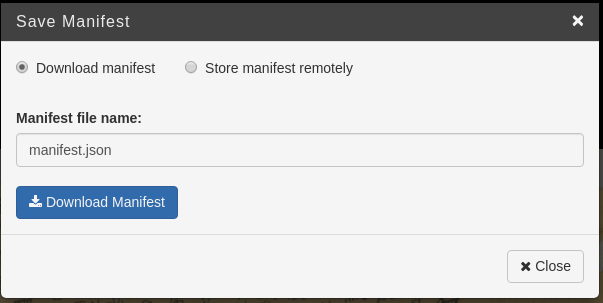
Wenn man keine weitere Eigenschaften (wie z.B. Laufrichtung der Bilder usw.) bestimmen will, kann man das Manifest downloaden, indem man zuerst «Save manifest» klickt und danach (wie oben) das Manifest herunterlädt. Man erhält dadurch ein JSON-Datei auf dem lokalen Arbeitsplatz.
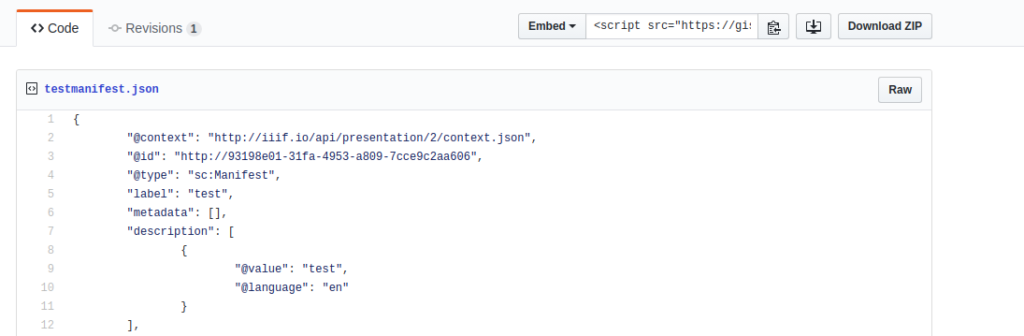
Dieses JSON-Datei (ich benenne es «testmanifest.json») lädt man auf den Internetserver hoch. Für das Manifest muss auch CORS (Cross-Origin Resource Sharing) ermöglicht sein. Hier könnt ihr mein hochgeladenes Manifest ansehen. … Fertig! Zum guten Schluss schauen wir die durch das Manifest zusammengestellten Bilder an, indem wir z.B. das URL des eigenen Manifest in den UV (Universal Viewer) hineintun und die Bilder anzeigen lassen:
Glückwunsch! Ihr habt damit ein Manifest im IIIF-Standard veröffentlicht!
Wie man hier am Beispiel sieht, können IIIF-Bilder – egal von welchem Server sie stammen mögen – durch Manifest zusammengeführt und als ein «Item» präsentiert werden. Dies ist eine Stärke vom IIIF.
Wenn man noch keinen Server für IIIF-Manifest habt, könnt ihr z.B. bei Github (unter «gist») das IIIF-Manifest hochladen.
Github
Wenn man das Manifest in GithubGist hochlädt und die Datei aufmacht, sieht es so aus. Dann «Row»-Button (unten) klicken.
Sieht so aus…
So wird die Manifest/JSON-Datei im Browser angezeigt. Diese URL sieht es so aus:
Die URL gilt als URL zum IIIF-Manifest. Daher kann man diese Link in einem beliebigen IIIF-Viewer hinentun und anzeigen lassen. Zum Beispiel dies:
Wenn’s klappt, ist das Manifest vollständig:)
In diesem Prozess habt ihr sicher bemerkt, dass man die IIIF-Bilder nicht selbst hochladen muss, solange man die IIIF-Bilder von einem dritten Anbieter für ein neues Manifest benutzt. Ihr könnt zum Beispiel so ein neues Manifest mit verschiedenen Bildern kreieren – Wie ein virtuelles Museum. Aber bitte dabei auf die Urheberrechte oder sonstige rechtliche Angaben zur Nutzung der Bilder achten.
Wer sich noch weiter über IIIF-Manifest vertiefen will, könnte man demnächst die Beschreibung von Presentation API von IIIF (unter §5 Resource structure – § 5.1 Manifest [link]) ansehen. Dort steht es, dass der Identifikator von einem Manifest eine empfohlene Form gibt.
Recommended URI pattern:
{scheme}://{host}/{prefix}/{identifier}/manifest
[…] The identifier in @id must always be able to be dereferenced to retrieve the JSON description of the manifest, and thus must use the http(s) URI scheme.
Dementsprechend könnte man überlegen, wie man der Identifikator einem Manifest vergibt und wie die URL leitet. Dies gilt auch für eine AnnotationList [link]…
In den bisherigen Blog haben wir beschrieben, wie man ein Bild-Datei nach dem IIIF-Standard im Internet publizieren kann (mit Hilfe von Cantaloupe Image Server). Die meisten IIIF-Viewer, wie Mirador oder Universal Viewer, verlangen jedoch IIIF-Manifest.
Aus der offiziellen Seiten von Universal Viewer. Dort kann man IIIF-Bilder ansehen. In der Suchschlitze muss man aber die URL zu einem IIIF-Manifest eingeben
Was ist eigentlich IIIF-Manifest?
Was IIIF-Manifest ist, ist in IIIF Presentation API beschrieben. Demnach gehört IIIF-Manifest zu dem Basic-Typen der IIIF-Ressourcen. Wir schauen die weiteren Definition:
The overall description of the structure and properties of the digital representation of an object. It carries information needed for the viewer to present the digitized content to the user, such as a title and other descriptive information about the object or the intellectual work that it conveys. Each manifest describes how to present a single object such as a book, a photograph, or a statue.
Also erst durch IIIF-Manifest wird festgelegt, wie das Objekt (hier vor allem Bild/Bilder) in einem IIIF-Viewer dargestellt werden soll. Daher ist das IIIF-Manifest für IIIF-Viewer wichtig. Die einfache Struktur eines IIIF-Manifestes sieht so aus:
IIIF-Manifest ist nach JSON-LD erfasst. … Also JSON (JavaScript Object Notation) ist ein Datenformat, das für Menschen (mehr oder weniger) lesbar und schreibbar ist und das auch Datenaustausch praktisch formatiert ist. «LD» von JSON-LD steht «Linked Data». Dieses Format ist also für Semantic Web gedacht… (Sorry, ich bin leider nicht wirklich Expert…)
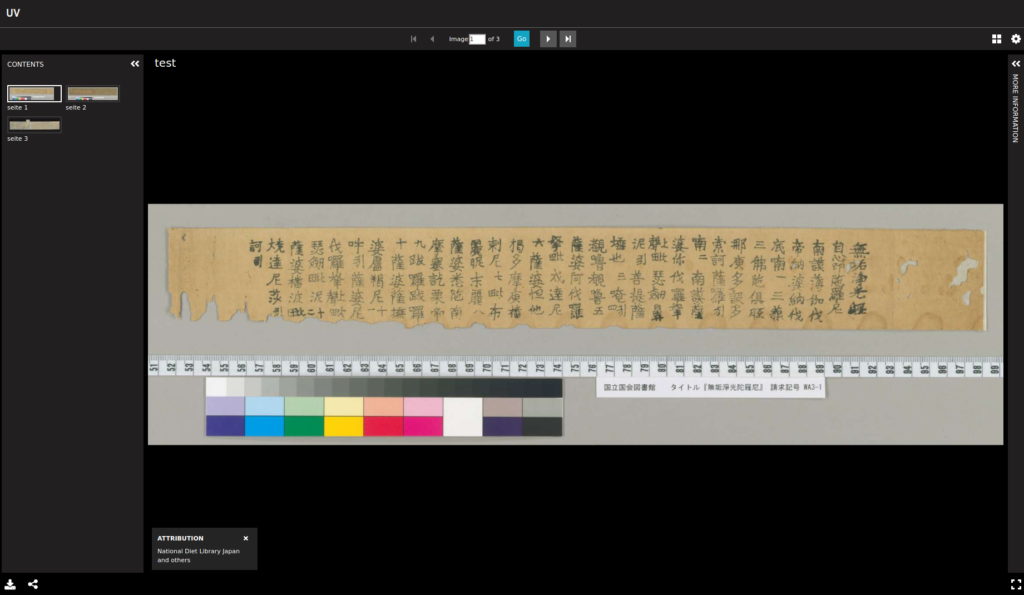
Als Beispiel habe ich eine alte Sutra «無垢淨光陀羅» von der National Diet Library Japan (NDL) mit UV(Universal Viewer) oben gezeigt. Wie man in der Webseite der NDL sieht, ist die URL zum IIIF-Manifest auch dort angezeigt.
Wegen Übersichtlichkeit sollt ihr vielleicht das ganze Manifest im neuen Tab im Browser anzeigen. Bei diesem Beispiel wissen wir bereits, dass wir hier 2 Bilder unter einem Titel subsumiert sind. In der ersten Hälfte des Manifestes (bis zur Zeile «»seeAlso»: […]) ist die Metadaten über diesen Titel beschrieben. Danach kommt Property «sequences». Dann im sequences sind noch «canvases» zu sehen. Weiter in einem Canvas findet ihr noch [Contents-]»resource». Diese Struktur, von oben her manifest – sequences – canvases – contents, haben wir bereits oben in der Illustration gesehen. Dies ist eine grobe Struktur von einem einfachen Manifest. Es gibt nähere Erläuterung wie hier von Jack Reed (Englisch). Welche Properties man für IIIF-Manifest verwenden kann, könnt ihr hier nachschauen.
Wie schreibt man ein IIIF-Manifest?
Wir wissen nun ungefähr, wie ein Manifest ausschaut. Die nächste Frage ist ja, wie schreibt man so ein Manifest? Man kann natürlich mit einem Code-Editor oder gar Text-Editor ein IIIF-Manifest erfassen. Wenn man aber sehr viel digitale Objekte hat, ist diese Methode nicht praktisch. Man erstellt Manifest eher maschinell. Was ich im nächsten Beitrag vorstelle, ist daher eine zweitbeste Lösung. – Manuelle Erfassung eines Manifests mit IIIF Manifest Editor.
Ich habe die neuere Version (4.1.1) vom Cantaloupe implementiert. Die Version 4.1.1 ist jetzt (11.5.2019) die neueste. Ab der Version 4.1.x ist «Access-Control-Allow-Origin»-Header immer dabei. Somit ermöglicht sie immer CORS, ohne dafür etwas zu konfigurieren. Die Version davor (z.B. 4.0.x) verlangte das «Origin»-Head im Request. Sonst lehnt der Server ab, die Access-Control-Allow-Origin-Zeile hinzufügen (https://github.com/cantaloupe-project/cantaloupe/issues/266).
Parallel zu diesem Update habe ich CORS für IIIF-Manifestation freigeschaltet. Diese Maßnahme ermöglicht die hier publizierten Bilder in einem IIIF-Viewer geöffnet und bearbeitet werden, der auf einem anderen Server funktioniert.
Im letzten Beitrag wurde alle notwendige shell scripts geschrieben und die Berechtigungen für ihre Ausführung sind konfiguriert. Es bleibt nur noch die Automatisierung dieses Prozesses.
Weil der Befehl für certbot-auto die root-Berechtigung fordert, muss cron mit sudo geführt werden. (Ich gehe hier davon aus, dass man hier nicht als root-user arbeitet.)
$ sudo crontab -e
Dadurch, dass der Befehl mit sudo aufgerufen wird, werden die in crontab aufgelisteten Befehle immer mit sudo ausgeführt.
In der Tabelle trägt man den shell script-Befehl wie folgt:
Bei default sudo-Einstellung bekommt dieser cron-Befehl ein Problem, weil bei einer sudo-Ausführung das Passwort des users im Terminal verlangt wird. Daher muss die sudo-Einstellung geändert werden.
$ sudo visudo
Mit visudo geht man in die sudo-Einstellung. Dann fügt man die folgenden zwei Zeilen hinzu:
Im letzen Beitrag wurde SSL-Zertifizierung durch Let’s encrypt erläutert. Weil das Zertifikat jedoch nur 90 Tage lang hält, wäre es praktisch dieser Zertifizierungsprozess automatisieren.
Dafür werden ein Paar shell script gebastelt… Es sind folgende 3 shell script geschrieben:
#Falls man jks-keystore-File in den Cantaloupe-Ordner bewegen möchte, soll man das #-Zeichen der nächsten Zeile löschen. #mv -f $jksname $serverpath
Passwörter, Passwort A und B, sollen den Passwörter entsprechen, die im Datei «cantaloupe.properties» eingegeben sind. Dort in cantaloupe.properties sind zwei Felder, «https.key_store_password» und «https.key_password».
Das zweite shell script steht dafür, dass cantaloupe-imageserver nach der Erneuerung des Zertifikats einmal gestoppt und wiedergestartet wird.
#!/bin/bash
# für stoppen
path="/path/to/Cantaloupe-Ordner"
targetpath="$path/cantaloupe-4.0.2.war"
cd $path
echo "Stop $targetpath server."
pkill -f cantaloupe
# für starten
echo "restart $targetpath server."
nohup java -Dcantaloupe.config=$path/cantaloupe.properties -Xmx3g -jar $targetpath &
Mit pkill-Befel stoppt der Prozess, dessen Name «cantaloupe» enthält. Ich habe hier max. 3GB dem heap space von JVM zugeteilt. Je nach Bedarf sollte man mehr Speicherkapazität zuweisen. (Hier siehe auch Cantaloupe-Hilfe.)
Das letzte shell script fasst die beiden Prozesse zusammen, und vor diesen zwei Prozesse ist «certbot-auto renew»-Befehl hineingeschoben:
Hier habe ich mir einen «Cantaloupe»-Ordner vorgestellt, der das war-File (z.B. cantaloupe-4.0.2.war) und all die oben genannten shell script-Daten beinhaltet.
Die shell script-Daten sollen nun für Ausführung freigeschaltet sein (z.B. mit «chmod 755»).
Um zu prüfen, ob dies alles funktioniert, kann man in der Zeile des certbot-Befehls noch die Option «–force-renewal» hinzufügen:
In createKey_and_restart_test_sample.sh ist die ganze Test-Datei zu sehen. Weil root-Berechtigung für certbot-auto-Befehl notwendig ist, soll man Test-Befehl so formulieren:
$ sudo ./createKey_and_restart_test_sample.sh
Wenn dieser Test-Befehl problemlos läuft, muss man nur noch den Prozess durch «cron» automatisieren…